Мы часто пишем о том, что снапшоты в VMware vSphere - это плохо (за исключением случаев, когда они используются для горячего резервного копирования виртуальных машин и временного сохранения конфигурации ВМ перед обновлением).
Однако их использование в крупных инфраструктурах неизбежно. Рано или поздно возникает необходимость удаления/консолидации снапшотов виртуальной машины (кнопка Delete All в Snapshot Manager), а процесс этот достаточно длительный и требовательный к производительности хранилищ, поэтому неплохо бы заранее знать, сколько он займет.
Напомним, что инициирование удаления снапшотов в vSphere Client через функцию Delete All приводит к их удалению из GUI сразу же, но на хранилище процесс идет долгое время. Но если в процесс удаления возникнет ошибка, то файлы снапшотов могут остаться на хранилище. Тогда нужно воспользоваться функцией консолидации снапшотов (пункт контекстного меню Consolidate):
О процессе консолидации снапшотов мы также писали вот тут. Удаление снапшотов (как по кнопке Delete All, так и через функцию Consolidate) называется консолидацией.
Сначала посмотрим, какие факторы влияют на время процесса консолидации снапшотов виртуальной машины:
Размер дельта-дисков - самый важный параметр, это очевидно. Чем больше данных в дельта-диске, тем дольше их нужно применять к основному (базовому) диску.
Количество снапшотов (число дельта-файлов) и их размеры. Чем больше снапшотов, тем больше метаданных для анализа перед консолидацией. Кроме того, при нескольких снапшотах консолидация происходит в несколько этапов.
Производительность подсистемы хранения, включая FC-фабрику, Storage Processor'ы хранилищ, LUN'ы (число дисков в группе, тип RAID и многое другое).
Тип данных в файлах снапшотов (нули или случайные данные).
Нагрузка на хост-сервер ESXi при снятии снапшота.
Нагрузка виртуальной машины на подсистему хранения в процессе консолидации. Например, почтовый сервер, работающий на полную мощность, может очень долго находится в процессе консолидации снапшотов.
Тут надо отметить, что процесс консолидации - это очень требовательный к подсистеме ввода-вывода процесс, поэтому не рекомендуется делать это в рабочие часы, когда производственные виртуальные машины нагружены.
Итак, как можно оценивать производительность процесса консолидации снапшотов:
Смотрим на производительность ввода-вывода хранилища, где находится ВМ со снапшотами.
Для реализации этого способа нужно, чтобы на хранилище осталась только одна тестовая виртуальная машина со снапшотами. С помощью vMotion/Storage vMotion остальные машины можно с него временно убрать.
1. Сначала смотрим размер файлов снапшотов через Datastore Browser или с помощью следующей команды:
ls -lh /vmfs/volumes/DATASTORE_NAME/VM_NAME | grep -E "delta|sparse"
2. Суммируем размер файлов снапшотов и записываем. Далее находим LUN, где размещена наша виртуальная машина, которую мы будем тестировать (подробнее об этом тут).
3. Запускаем команду мониторинга производительности:
# esxtop
4. Нажимаем клавишу <u> для переключения в представление производительности дисковых устройств. Для просмотра полного имени устройства нажмите Shift + L и введите 36.
5. Найдите устройство, на котором размещен датастор с виртуальной машиной и отслеживайте параметры в колонках MBREAD/s и MBWRTN/s в процессе консолидации снапшотов. Для того, чтобы нужное устройство было вверху экрана, можно отсортировать вывод по параметру MBREAD/s (нажмите клавишу R) or MBWRTN/s (нажмите T).
Таким образом, зная ваши параметры производительности чтения/записи, а также размер снапшотов и время консолидации тестового примера - вы сможете оценить время консолидации снапшотов для других виртуальных машин (правда, только примерно того же профиля нагрузки на дисковую подсистему).
Смотрим на производительность конкретного процесса консолидации снапшотов.
Это более тонкий процесс, который можно использовать для оценки времени снапшота путем мониторинга самого процесса vmx, реализующего операции со снапшотом в памяти сервера.
1. Запускаем команду мониторинга производительности:
# esxtop
2. Нажимаем Shift + V, чтобы увидеть только запущенные виртуальные машины.
3. Находим ВМ, на которой идет консолидация.
4. Нажимаем клавишу <e> для раскрытия списка.
5. Вводим Group World ID (это значение в колонке GID).
6. Запоминаем World ID (для ESXi 5.x процесс называется vmx-SnapshotVMX, для ранних версий SnapshotVMXCombiner).
7. Нажимаем <u> для отображения статистики дискового устройства.
8. Нажимаем <e>, чтобы раскрыть список и ввести устройство, на которое пишет процесс консолидации VMX. Что-то вроде naa.xxx.
9. Смотрим за процессом по World ID из пункта 6. Можно сортировать вывод по параметрам MBREAD/s (клавиша R) или MBWRTN/s (клавиша T).
10. Отслеживаем среднее значение в колонке MBWRTN/s.
Это более точный метод оценки и его можно использовать даже при незначительной нагрузке на хранилище от других виртуальных машин.
Напомним, что Veeam Availability Suite - это самое продвинутое в отрасли решение для всесторонней защиты данных средствами резервного копирования и репликации, а также набор продуктов для управления и мониторинга виртуальной среды. По-сути, это все что нужно, кроме самой платформы VMware vSphere или Microsoft Hyper-V, чтобы организовать виртуальный датацентр с непрерывной доступностью сервисов в виртуальных машинах.
Приведем ниже основные новые возможности Veeam Availability Suite v9, касающиеся его основного компонента - Veeam Backup and Replication 9:
1. Интеграция с технологией EMC Storage Snapshots в Veeam Availability Suite v9.
Многие пользователи Veeam Backup and Replication задавали вопрос, когда же будет сделана интеграция с дисковыми массивами EMC. Теперь она добавлена для СХД линеек EMC VNX и EMC VNXe.
Интеграция с хранилищами EMC означает поддержку обеих техник - Veeam Explorer for Storage Snapshots recovery и Backup from Storage snapshots, то есть можно смотреть содержимое снапшотов уровня хранилища и восстанавливать оттуда виртуальные машины (и другие сущности - файлы или объекты приложений), а также делать бэкап из таких снапшотов.
Иллюстрация восстановления из снапшота на хранилище EMC:
Иллюстрация процесса резервного копирования (Veeam Backup Proxy читает данные напрямую со снапшота всего тома, сделанного на хранилище EMC):
Более подробно об этих возможностях можно почитать в блоге Veeam.
2. Veeam Cloud Connect - теперь с возможностью репликации.
Как вы помните, в прошлом году компания Veeam выпустила средство Veeam Cloud Connect, которое позволяет осуществлять резервное копирование в облако практически любого сервис-провайдера. Теперь к этой возможности прибавится еще и возможность репликации ВМ в облако, что невероятно удобно для быстрого восстановления работоспособности сервисов в случае большой или маленькой беды:
Кстати, Veeam Cloud Connect инкапуслирует весь передаваемый трафик в один-единственный порт, что позволяет не открывать диапазоны портов при соединении с инфраструктурой сервис-провайдера. Очень удобно.
При восстановлении в случае аварии или катастрофы основного сайта, возможно не только полное восстановление инфраструктуры, но и частичное - когда часть продуктивной нагрузки запущено на основной площадке, а другая часть (например, отказавшая стойка) - на площадке провайдера. При этом Veeam Backup обеспечивает сетевое взаимодействие между виртуальными машинами обеих площадок за счет встроенных компонентов (network extension appliances), которые обеспечивают сохранение единого пространства адресации.
Ну а сервис-провайдеры с появлением репликации от Veeam получают в свои руки полный спектр средств для организации DR-площадки в аренду для своих клиентов:
Более подробно об этой возможности можно прочитать в блоге Veeam по этой ссылке.
3. Прямой доступ к хранилищам NAS/NFS при резервном копировании.
Veeam Availability Suite v9 поддерживает прямой доступ к хранилищам NAS/NFS при резервном копировании. Раньше пользователи NFS-массивов чувствовали себя несколько "обделенными" в возможностях, так как Veeam не поддерживал режим прямой интеграции с таким типом дисковым массивов, как это было для блочных хранилищ.
Теперь же появилась штука, называемая Direct NFS, позволяющая сделать резервную копию ВМ по протоколам NFS v3 и новому NFS 4.1 (его поддержка появилась только в vSphere 6.0), не задействуя хост-сервер для копирования данных:
Специальный клиент NFS (который появился еще в 8-й версии) при включении Direct NFS получает доступ к файлам виртуальных машин на томах, для которых можно делать резервное копирование и репликацию без участия VMware ESXi, что заметно повышает скорость операций.
Кроме этого, была улучшена поддержка дисковых массивов NetApp. В версии 9 к интеграции с NetApp добавилась поддержка резервного копирования из хранилищ SnapMirror и SnapVault. Теперь можно будет создавать аппаратные снимки (с учетом состояния приложений) с минимальным воздействием на виртуальную среду, реплицировать точки восстановления на резервный дисковый массив NetApp с применением техник SnapMirror или SnapVault, а уже оттуда выполнять бэкап виртуальных машин.
При этом процесс резервного копирования не отбирает производительность у основной СХД, ведь операции ввода-вывода происходят на резервном хранилище:
Ну и еще одна полезная штука в плане поддержки аппаратных снимков хранилищ от Veeam. Теперь появится фича Sandbox On-Demand, которая позволяет создать виртуальную лабораторию, запустив виртуальные машины напрямую из снапшотов томов уровня хранилищ. Такая лаборатория может быть использована как для проверки резервных копий на восстановляемость (сразу запускаем ВМ и смотрим, все ли в ней работает, после этого выключаем лабораторию, оставляя резервные копии неизменными), так и для быстрого клонирования наборов сервисов (создали несколько ВМ, после чего создали снапшот и запустили машины из него). То есть, можно сделать как бы снимок состояния многомашинного сервиса (например, БД-сервер приложений-клиент) и запустить его в изолированном окружении для тестов, ну или много чего еще можно придумать.
Вот здесь вы можете узнать больше подробностей об этой возможности в блоге Veeam.
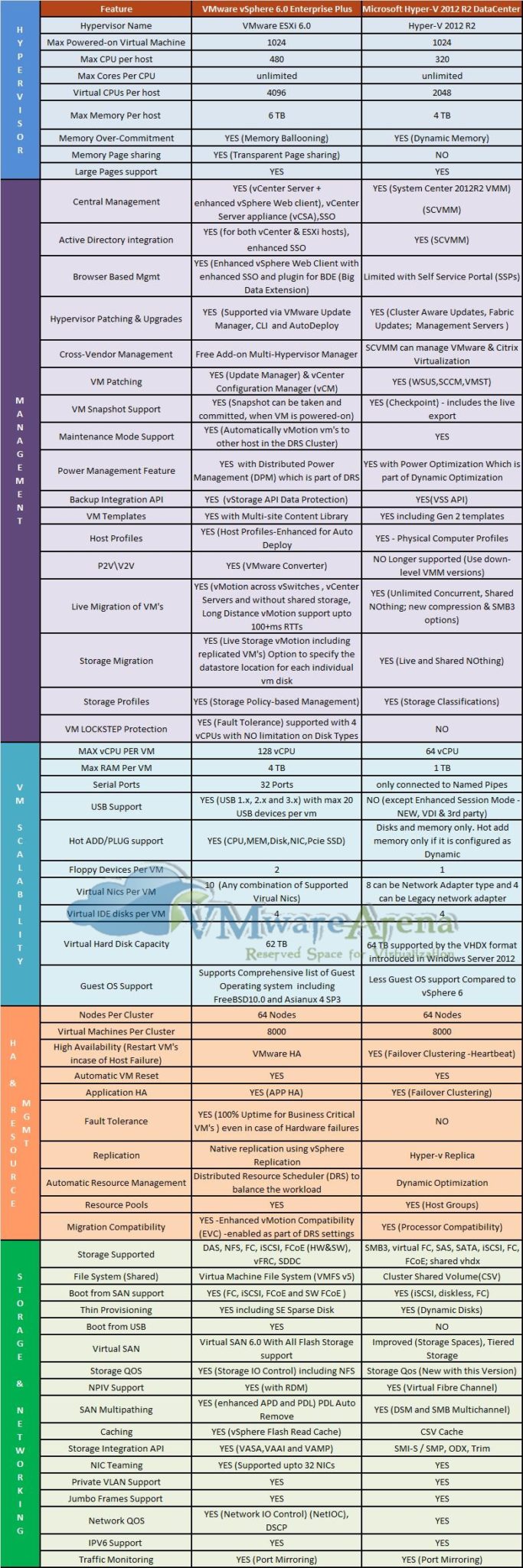
Не так давно на сайте VMwareArena появилось очередное сравнение VMware vSphere (в издании Enterprise Plus) и Microsoft Hyper-V в Windows Server 2012 R2 Datacenter Edition, которое включает в себя самую актуальную информацию о возможностях обеих платформ.
Мы адаптировали это сравнение в виде таблицы и представляем вашему вниманию ниже:
Группа возможностей
Возможность
VMware vSphere 6
Enterprise Plus
Microsoft Hyper-V в Windows Server 2012 R2 Datacenter Edition
Возможности гипервизора
Версия гипервизора
VMware ESXi 6.0
Hyper-V 2012 R2
Максимальное число запущенных виртуальных машин
1024
1024
Максимальное число процессоров (CPU) на хост-сервер
480
320
Число ядер на процессор хоста
Не ограничено
Не ограничено
Максимальное число виртуальных процессоров (vCPU) на хост-сервер
4096
2048
Максимальный объем памяти (RAM) на хост-сервер
6 ТБ
4 ТБ
Техники Memory overcommitment (динамическое перераспределение памяти между машинами)
Memory ballooning
Dynamic Memory
Техники дедупликации страниц памяти
Transparent page sharing
Нет
Поддержка больших страниц памяти (Large Memory Pages)
Да
Да
Управление платформой
Централизованное управление
vCenter Server + vSphere Client + vSphere Web Client, а также виртуальный модуль vCenter Server Appliance (vCSA)
System Center Virtual Machine Manager (SC VMM)
Интеграция с Active Directory
Да, как для vCenter, так и для ESXi-хостов через расширенный механизм SSO
Да (через SC VMM)
Поддержка снапшотов (VM Snapshot)
Да, снапшоты могут быть сделаны и удалены для работающих виртуальных машин
Да, технология Checkpoint, включая функции live export
Управление через браузер (тонкий клиент)
Да, полнофункциональный vSphere Web Client
Ограниченное, через Self Service Portal
Обновления хост-серверов / гипервизора
Да, через VMware Update Manager (VUM), Auto Deploy и CLI
Да - Cluster Aware Updates, Fabric Updates, Management Servers
Управление сторонними гипервизорами
Да, бесплатный аддон Multi-Hypervisor Manager
Да, управление VMware vCenter и Citrix XenCenter поддерживается в SC VMM
Обновление (патчинг) виртуальных машин
Да, через VMware Update Manager (VUM) и vCenter Configuration Manager (vCM)
Да (WSUS, SCCM, VMST)
Режим обслуживания (Maintenance Mode)
Да, горячая миграция ВМ в кластере DRS на другие хосты
Да
Динамическое управление питанием
Да, функции Distributed Power Management в составе DRS
Да, функции Power Optimization в составе Dynamic Optimization
API для решений резервного копирования
Да, vStorage API for Data Protection
Да, VSS API
Шаблоны виртуальных машин (VM Templates)
Да + Multi-site content library
Да, включая шаблоны Gen2
Профили настройки хостов (Host Profiles)
Да, расширенные функции host profiles и интеграция с Auto Deploy
Да, функции Physical Computer Profiles
Решение по миграции физических серверов в виртуальные машины
Да, VMware vCenter Converter
Нет, больше не поддерживается
Горячая миграция виртуальных машин
Да, vMotion между хостами, между датацентрами с разными vCenter, Long Distance vMotion (100 ms RTT), возможна без общего хранилища
Да, возможна без общего хранилища (Shared Nothing), поддержка компрессии и SMB3, неограниченное число одновременных миграций
Горячая миграция хранилищ ВМ
Да, Storage vMotion, возможность указать размещение отдельных виртуальных дисков машины
Да
Профили хранилищ
Да, Storage policy-based management
Да, Storage Classifications
Кластер непрерывной доступности ВМ
Да, Fault Tolerance с поддержкой до 4 процессоров ВМ, поддержка различных типов дисков, технология vLockstep
Нет
Конфигурации виртуальных машин
Виртуальных процессоров на ВМ
128 vCPU
64 vCPU
Память на одну ВМ
4 ТБ
1 ТБ
Последовательных портов (serial ports)
32
Только присоединение к named pipes
Поддержка USB
До 20 на одну машину (версии 1,2 и 3)
Нет (за исключением Enhanced Session Mode)
Горячее добавление устройств
(CPU/Memory/Disk/NIC/PCIe SSD)
Только диск и память (память только, если настроена функция Dynamic memory)
Диски, растущие по мере наполнения данными (thin provisioning)
Да (thin disk и se sparse)
Да, Dynamic disks
Поддержка Boot from USB
Да
Нет
Хранилища на базе локальных дисков серверов
VMware Virtual SAN 6.0 с поддержкой конфигураций All Flash
Storage Spaces, Tiered Storage
Уровни обслуживания для подсистемы ввода-вывода
Да, Storage IO Control (работает и для NFS)
Да, Storage QoS
Поддержка NPIV
Да (для RDM-устройств)
Да (Virtual Fibre Channel)
Поддержка доступа по нескольким путям (multipathing)
Да, включая расширенную поддержку статусов APD и PDL
Да (DSM и SMB Multichannel)
Техники кэширования
Да, vSphere Flash Read Cache
Да, CSV Cache
API для интеграции с хранилищами
Да, широкий спектр VASA+VAAI+VAMP
Да, SMI-S / SMP, ODX, Trim
Поддержка NIC Teaming
Да, до 32 адаптеров
Да
Поддержка Private VLAN
Да
Да
Поддержка Jumbo Frames
Да
Да
Поддержка Network QoS
Да, NetIOC (Network IO Control), DSCP
Да
Поддержка IPv6
Да
Да
Мониторинг трафика
Да, Port mirroring
Да, Port mirroring
Подводя итог, скажем, что нужно смотреть не только на состав функций той или иной платформы виртуализации, но и необходимо изучить, как именно эти функции реализованы, так как не всегда реализация какой-то возможности позволит вам использовать ее в производственной среде ввиду различных ограничений. Кроме того, обязательно нужно смотреть, какие функции предоставляются другими продуктами от данного вендора, и способны ли они дополнить отсутствующие возможности (а также сколько это стоит). В общем, как всегда - дьявол в деталях.
Таги: VMware, vSphere, Hyper-V, Microsoft, Сравнение, ESXi, Windows, Server
Это гостевой пост сервис-провайдера 1cloud, предоставляющего услуги облачной аренды виртуальных машин. Ранее они рассказывали о развитии данной технологии в статье о «революции контейнеров» в своем блоге на Хабре.
Шумиха вокруг контейнеров последнего времени поставила один важный вопрос: как эта технология сможет ужиться с традиционными вариантами управления инфраструктурой, и какие угрозы она таит для рынка виртуализации? И даже более конкретный: заменят ли контейнеры виртуальные машины?
На ежегодной конференции в Сан-Франциско, прошедшей на в сентябре 2015 года, VMware дала однозначно понять, что этого не произойдет. Новая платформа управления вводит новый тип виртуализации — для самих контейнеров.
Виртуализация для контейнеров
Полтора десятка лет назад VMware взорвала технологическую индустрию, выпустив свой корпоративный гипервизор, открывший эпоху серверной виртуализации. На прошлой неделе компания представила обновленную версию своей классической программы для виртуализации под названием Project Photon. По сути, это облегченная реплика популярного гипервизора ESX компании, разработанная специально для работы с приложениями в контейнерной реализации.
«В ее основе, по-прежнему, лежит принцип виртуализации», — объясняет вице-президент VMware и технический директор Cloud Native Applications Кит Колберт. Он предпочитает называть Photon «микровизором» с достаточным набором функций для успешной виртуализации, упакованный в удобный для контейнеров формат.
Project Photon состоит из двух ключевых элементов. Photon Machine – оболочка для гипервизора, дублирующая ESX и устанавливаемая напрямую на физические серверы. Она создает виртуальную машину в миниатюре, куда помещаются контейнеры. Пользователь может самостоятельно выбрать гостевую ОС. По умолчанию устанавливается Photon ОС под Linux, которую компания также сделала совместимой с технологией контейнеров.
Второй элемент – это Photon Controller, мультитенантный маршрутизатор, позволяющий управлять одновременно дюжинами, если не тысячами, объектов на Photon Machine. Он следит за тем, чтобы все блоки (кластеры) Photon Machine имели доступ к сети и базам данных, когда это необходимо.
Комбинация этих двух элементов задает шаблон для масштабируемой среды и имеет надстройку для написания API. В теории, IT-операторы могу усовершенствовать Project Photon, и сами разработчики создавать на его базе приложения.
Project Photon способен интегрироваться с открытыми программами. Например, с Docker’ом для поддержки исполнения программы, или с Google Kubernetes и Pivotil’s Cloud Foundry для более качественного управления приложениями. Photon в данном случае выполняет подготовку инфраструктуры, а Kubernetes и CF занимаются развертыванием приложений.
В прошлом году для индивидуальных пользователей платформа стала доступна в качестве бета-версии.
Долгая дорога к контейнерам
Не все пользователи готовы полностью переключиться на контейнерную реализацию. Поэтому VMware для сомневающихся интегрирует поддержку контейнеров с традиционными инструментами управления.
vSphere Integrated Containers – еще один продукт, анонсированный на конференции. Как пояснил Кит Колберт, это идеальный вариант для тех, кто только хочет начать экспериментировать с контейнерами. Для желающих же использовать возможности контейнеров по максимуму он рекомендует переход к Project Photon.
vSphere Integrated Containers представляет собой плагин для vSphere, установленной на достопочтенном ESX компании. «Он делает контейнеры самыми желанными гостями платформы», — уточняет Колберт. При помощи плагина пользователи могут устанавливать контейнеры внутрь виртуальной машины, позволяя управлять ею так же, как и любой другой в пространстве платформы виртуализации.
В текущих условиях, если пользователь решил загрузить контейнеры в vSphere, ему приходится все скопом помещать их в одну единственную виртуальную машину. Таким образом, если что-то случится с одним из контейнеров, повреждения могут получить и все остальные, находящиеся в ВМ. Распределение контейнеров по разным ВМ обеспечивает их сохранность и аккуратное управление платформой.
Аналитик Marko Insights Курт Марко говорит, что новый подход к контейнерной реализации VMware должен облегчить жизнь и самим администраторам платформы. «Работа с контейнерами Photon в формате микро-ВМ схожа с тем, как работают с классом стеков и операторов, — сообщает Марко в своем письме. – Конечно, здесь могут быть потери в производительности, поскольку даже микро-ВМ будут больше перегружены, чем контейнеры, пользующиеся одними ядрами и библиотеками. В самой VMware утверждает, что это проблемой можно пренебречь, но Марко настаивает на независимом анализе издержек работы с контейнерами внутри виртуальных машин.
Не все так быстро
В VMware полны энтузиазма и рассматривают себя в качестве флагмана контейнерной реализации. Но есть несколько моментов, способных этот порыв охладить. Во-первых, вероятно, рынок контейнеров еще к этому не готов.
«Реклама продукта пока обгоняет реальность», — говорит аналитик IDC Эл Гиллен. По его подсчетам, менее десятой доли процента корпоративных приложений сейчас делаются через контейнеры. Может пройти десятилетие, пока рынок переварит эти технологии, и цифра приблизится к 40%.
Во-вторых, VMware никогда не обладала репутацией компании, готовой быть в авангарде разработок открытого программного обеспечения и проектов. Скорее, наоборот. Соучредитель и исполнительный директор Rancher Labs (стартапа, внедрившего свою ОС для контейнеров на VMworld) Шен Льян говорит, что до этого момента контейнерную реализацию продвигали сами разработчики или открытые платформы, наподобие Mesos, Docker и Kubernetes. Он добавил, что не встречал еще ни одного человека, использующего в работе контейнеры, который бы делал это с помощью инструментария VMware.
Аналитик Forrester Дейв Бартолти не удивлен данному обстоятельству. В VMware налажены прочные связи с проектными ИТ-менеджерами, но не с разработчиками, активно использующими контейнеры. Новинки, которые компания представила на VMworld, должны как раз вдохновить первых активно использовать контейнеры в рамках работы с платформой VMware. Остальные вендоры, среди которых Red Hat, Microsoft и IBM, также с удовольствием пользуются этой процедурой. VMware настаивает, что нашла способ примерить виртуальные машины и контейнеры.
Продолжаем рассказывать о решении номер 1 для создания программных хранилищ под виртуализацию VMware и Microsoft - StarWind Virtual SAN. Сегодня мы расскажем о том, как корректно настроить механизм доступа к хранилищам по нескольким путям MPIO (Multi-Path Input/Output) на сервере хранения Windows Server 2012.
Сначала необходимо убедиться, что возможность MPIO установлена на сервере, и, если нет, то установить ее:
Открываем Server Manager.
Нажимаем кнопку "Manage" в правом верхнем углу и выбираем "Add Roles and Features".
Нажимаем Next в первой странице мастера.
В части Installation Type выбираем "Role-based or feature-based installation".
На странице Server Selection выбираем нужный сервер, где хотим включить MPIO (по умолчанию этот сервер).
В разделе Features отмечаем галкой "Multipath I/O" и жмем кнопку "Install".
После того, как вы добавили возможность MPIO на Windows Server, нужно включить ее поддержку для iSCSI-устройств, которые использует StarWind Virtual SAN:
Откройте настройку MPIO в средствах администрирования сервера.
Нажмите на вкладку "Discover Multi-Paths".
Поставьте галочку напротив "Add support for iSCSI devices".
Перезагрузите сервер.
Затем нужно настроить политику доступа по нескольким путям. StarWind рекомендует использовать политику "Fail Over Only", если сумма пропускных способностей ваших путей составляет менее 10 Гбит/с. В противном случае стоит использовать политику Round Robin в целях повышения производительности.
Более подробно о настройке MPIO для StarWind рассказано тут.
В новой книге Фрэнка на 300 страницах раскрываются следующие моменты, касающиеся производительности подсистемы хранения платформ виртуализации, построенной на базе локальных дисков хост-серверов:
Новая парадигма построения виртуального датацентра с точки зрения систем хранения
Архитектура решения FVP
Ускорение доступа к данным
Технология непрерывной доступности Fault Tolerance
Технология Flash
Техники доступа к памяти
Настройка кластера решения FVP
Сетевой дизайн инфраструктуры локальных хранилищ
Внедрение и пробная версия решения FVP
Дизайн инфраструктуры хранилищ
Несмотря на то, что книга рассматривает в качестве основного продукта решение FVP от компании PernixData, ее интересно читать и с точки зрения понимания архитектуры и производительности подобных решений.
Если вы посмотрите в документ VSAN Troubleshooting Reference Manual (кстати, очень нужный и полезный), описывающий решение проблем в отказоустойчивом кластере VMware Virtual SAN, то обнаружите там такую расширенную настройку, как VSAN.ClomMaxComponentSizeGB.
Когда кластер VSAN хранит объекты с данными виртуальных дисков машин, он разбивает их на кусочки, растущие по мере наполнения (тонкие диски) до размера, указанного в данном параметре. По умолчанию он равен 255 ГБ, и это значит, что если у вас физические диски дают полезную емкость меньше данного объема (а точнее самый маленький из дисков в группе), то при достижении тонким диском объекта предела физической емкости вы получите вот такое сообщение:
There is no more space for virtual disk XX. You might be able to continue this session by freeing disk space on the relevant volume and clicking retry.
Если, например, у вас физический диск на 200 ГБ, а параметры FTT и SW равны единице, то максимально объект виртуального диска машины вырастет до этого размера и выдаст ошибку. В этом случае имеет смысл выставить настройку VSAN.ClomMaxComponentSizeGB на уровне не более 80% емкости физического диска (то есть, в рассмотренном случае 160 ГБ). Настройку эту нужно будет применить на каждом из хостов кластера Virtual SAN.
Как это сделать (более подробно об этом - в KB 2080503):
В vSphere Web Client идем на вкладку Manage и кликаем на Settings.
Под категорией System нажимаем Advanced System Settings.
Выбираем элемент VSAN.ClomMaxComponentSizeGB и нажимаем иконку Edit.
Устанавливаем нужное значение.
Надо отметить, что изменение этой настройки работает только для кластера VSAN без развернутых на нем виртуальных машин. Если же у вас уже продакшен-инфраструктура столкнулась с такими трудностями, то вы можете воспользоваться следующими двумя способами для обхода описанной проблемы:
1. Задать Object Space Reservation в политике хранения (VM Storage Policy) таким образом, чтобы дисковое пространство под объекты резервировалось сразу (на уровне 100%). И тогда VMDK-диски будут аллоцироваться целиком и распределяться по физическим носителям по мере необходимости.
2. Задать параметр Stripe Width в политиках VM Storage Policy таким образом, чтобы объекты VMDK распределялись сразу по нескольким физическим накопителям.
Фишка еще в том, что параметрVSAN.ClomMaxComponentSizeGB не может быть выставлен в значение, меньшее чем 180 ГБ, а значит если у вас носители меньшего размера (например, All-Flash конфигурация с дисками меньше чем 200 ГБ) - придется воспользоваться одним из этих двух способов, чтобы избежать описанной ошибки. Для флеш-дисков 200 ГБ установка значения в 180 ГБ будет ок, несмотря на то, что это уже 90% физической емкости.
У большинства администраторов хотя бы раз была ситуация, когда управляющий сервер VMware vCenter оказывался недоступен. Как правило, этот сервер работает в виртуальной машине, которая может перемещаться между физическими хостами VMware ESXi.
Если вы знаете, где находится vCenter, то нужно зайти на хост ESXi через веб-консоль Embedded Host Client (который у вас должен быть развернут) и запустить/перезапустить ВМ с управляющим сервером. Если же вы не знаете, где именно ваш vCenter был в последний раз, то вам поможет вот эта статья.
Ну а как же повлияет недоступность vCenter на функционирование вашей виртуальной инфраструктуры? Давайте взглянем на картинку:
Зеленым отмечено то, что продолжает работать - собственно, виртуальные машины на хостах ESXi. Оранжевое - это то, что работает, но с некоторыми ограничениями, а красное - то, что совсем не работает.
Начнем с полностью нерабочих компонентов в случае недоступности vCenter:
Централизованное управление инфраструктурой (Management) - тут все очевидно, без vCenter ничего работать не будет.
DRS/Storage DRS - эти сервисы полностью зависят от vCenter, который определяет хосты ESXi и хранилища для миграций, ну и зависят от технологий vMotion/Storage vMotion, которые без vCenter не работают.
vMotion/SVMotion - они не работают, когда vCenter недоступен, так как нужно одновременно видеть все серверы кластера, проверять кучу различных условий на совместимость, доступность и т.п., что может делать только vCenter.
Теперь перейдем к ограниченно доступным функциям:
Fault Tolerance - да, даже без vCenter ваши виртуальные машины будут защищены кластером непрерывной доступности. Но вот если один из узлов ESXi откажет, то новый Secondary-узел уже не будет выбран для виртуальной машины, взявшей на себя нагрузку, так как этот функционал опирается на vCenter.
High Availability (HA) - тут все будет работать, так как настроенный кластер HA функционирует независимо от vCenter, но вот если вы запустите новые ВМ - они уже не будут защищены кластером HA. Кроме того, кластер HA не может быть переконфигурирован без vCenter.
VMware Distributed Switch (vDS) - распределенный виртуальный коммутатор как объект управления на сервере vCenter работать перестанет, однако сетевая коммуникация между виртуальными машинами будет доступна. Но вот если вам потребуется изменить сетевые настройки виртуальной машины, то уже придется прицеплять ее к обычному Standard Switch, так как вся конфигурация vDS доступна для редактирования только с работающим vCenter.
Other products - это сторонние продукты VMware, такие как vRealize Operations и прочие. Тут все зависит от самих продуктов - какие-то опираются на сервисы vCenter, какие-то нет. Но, как правило, без vCenter все довольно плохо с управлением сторонними продуктами, поэтому его нужно как можно скорее поднимать.
Для обеспечения доступности vCenter вы можете сделать следующее:
Защитить ВМ с vCenter технологией HA для рестарта машины на другом хосте ESXi в случае сбоя.
Использовать кластер непрерывной доступности VMware Fault Tolerance (FT) для сервера vCenter.
Представляем гостевой пост компании 1cloud, предоставляющей услуги в области хостинга виртуальных машин по модели IaaS. С падением цен на SSD все больше компаний предлагают массивы, целиком построенные на флеш-памяти, но действительно ли они лучше гибридных массивов, содержащих как твердотельные накопители, так и жесткие диски?
В блоге VMware появился интересный пост о производительности СУБД Microsoft SQL Server на облачной платформе VMware vCloud Air. Целью исследования было выявить, каким образом увеличение числа процессоров и числа виртуальных машин сказываются на увеличении производительности баз данных, которые во многих случаях являются бизнес-критичными приложениями уровня Tier 1 на предприятии.
В качестве тестовой конфигурации использовались виртуальные машины с числом виртуальных процессоров (vCPU) от 4 до 16, с памятью от 8 до 32 ГБ на одну ВМ, а на хост-серверах запускалось от 1 до 4 виртуальных машин:
На физическом сервере было 2 восьмиядерных процессора (всего 16 CPU), то есть можно было запустить до 16 vCPU в режиме тестирования линейного роста производительности (Hyper-Threading не использовался).
В качестве приложения использовалась база данных MS SQL с типом нагрузки OLTP, а сами машины размещались на хостинге vCloud Air по модели Virtual Private Cloud (более подробно об этом мы писали вот тут). Для создания стрессовой нагрузки использовалась утилита DVD Store 2.1.
Первый эксперимент. Увеличиваем число четырехпроцессорных ВМ на хосте от 1 до 4 и смотрим за увеличением производительности, выраженной в OPM (Orders Per Minute), то есть числе небольших транзакций в минуту:
Как видно, производительность показывает вполне линейный рост с небольшим несущественным замедлением (до 10%).
Второй эксперимент. Увеличиваем число восьмипроцессорных ВМ с одной до двух:
Здесь также линейный рост.
Замеряем производительность 16-процессорной ВМ и сводим все данные воедино:
Проседание производительности ВМ с 16 vCPU обусловлено охватом процессорами ВМ нескольких NUMA-узлов, что дает некоторые потери (да и вообще при увеличении числа vCPU удельная производительность на процессор падает).
Но в целом, как при увеличении числа процессоров ВМ, так и при увеличении числа виртуальных машин на хосте, производительность растет вполне линейно, что говорит о хорошей масштабируемости Microsoft SQL Server в облаке vCloud Air.
Кстати, если хочется почитать заказуху про то, как облака VMware vCloud Air уделывают Microsoft Azure и Amazon AWS, можно пройти по этим ссылкам:
Многие из вас, следящие за новостями о лучшем продукте для создания отказоустойчивых хранилищ StarWind Virtual SAN, часто задаются вопросом - а чем это решение лучше существующих аналогов от VMware и Microsoft? Первый и наиболее очевидный ответ - цена. Просто посмотрите на то, сколько стоит VMware VSAN, и сравните это со стоимостью лицензий StarWind. Разницу вы почувствуете сразу.
Но это еще не все. Компания StarWind выпустила полезный каждому сомневающемуся документ "StarWind Virtual SAN: Differentiation [from competitors]", в котором весьма подробно рассмотрены преимущества продукта перед решениями от маститых вендоров.
Например, почему StarWind Virtual SAN лучше VMware Virtual SAN:
Для работы отказоустойчивых хранилищ StarWind нужно всего 2 узла (VMware требует минимум 3). Плюс StarWind не требует какой-то особенной инфраструктуры типа поддержки 10G Ethernet или SSD-дисков. У StarWind все проще.
VMware Virtual SAN лицензируется по числу процессоров ESXi плюс требуются лицензии на сам ESXi. У StarWind лицензия выйдет дешевле - вы можете лицензировать по числу узлов кластера хранилищ, либо весь датацентр сразу, и использовать бесплатные издания ESXi.
Кластер VMware Virtual SAN вы можете использовать только для платформы vSphere, а StarWind Virtual SAN можно использовать для хранения виртуальных машин на базе любого гипервизора - хоть ESXi, хоть Hyper-V, хоть XenServer.
StarWind Virtual SAN - это продукт, который сейчас находится в 8-й версии, а Virtual SAN - это всего лишь вторая версия решения. Поскольку это решение относится к самому нижнему уровню сервисов хранения датацентра, надежность работы решения является определяющим факторов.
Более подробно об этом и других продуктах для сравнения, в частности, Microsoft Storage Spaces, Microsoft Scale-Out File Server, HP Lefthand VSA, DataCore SANsymphony, Maxta и PernixData, вы можете узнать непосредственно из документа.
Некоторое время назад мы писали об очень серьезном баге в технологии Changed Block Tracking, обеспечивающей работу инкрементального резервного копирования виртуальных машин VMware vSphere 6. Баг заключался в том, что операции ввода-вывода, сделанные во время консолидации снапшота ВМ в процессе снятия резервной копии, могли быть потеряны. Для первого бэкапа в этом нет ничего страшного, а вот вызываемая во второй раз функция QueryDiskChangedAreas технологии CBT не учитывала потерянные операции ввода-вывода, а соответственно при восстановлении из резервной копии такой бэкап был неконсистентным.
Мы писали про временное решение, заключающееся в отключении технологии CBT при снятии резервных копий продуктом Veeam Backup and Replication, но оно, конечно же, было неприемлемым, так как скорость бэкапов снижалась в разы, расширяя окно резервного копирования до неприличных значений.
И вот, наконец, вышло исправление этого бага, описанное в KB 2137545. Это патч для сервера VMware ESXi, который распространяется в виде стандартного VIB-пакета в сжатом zip-архиве.
Чтобы скачать патч, идите по этой ссылке, выберите продукт "ESXi Embedded and Installable" и введите в поле Enter Bulletin Number следующую строчку:
ESXi600-201511401-BG
Нажмите Search, после чего скачайте обновленный билд VMware ESXi 6.0 по кнопке Download:
Про патч в формате VIB-пакета написано вот тут, а про сам обновленный релиз ESXi вот тут. Для установки VIB на сервере ESXi используйте следующую команду:
На днях компания Microsoft выпустила очередное обновление технологического превью следующего поколения своей серверной платформы - Windows Sever 2016 Technical Preview 4 (а также и System Center 2016).
В новой версии появилось несколько важных нововведений, многие из которых непосредственно касаются технологий виртуализации:
1. Поддержка контейнеров приложений Windows Server Containers и Hyper-V Containers.
Эта поддержка появилась еще в Technical Preview 3, но в этом обновлении была существенно расширена. Напомним, что мы уже писали об этом вот тут. В новой версии Windows Server будут поддерживаться как контейнеры Docker на базе механизма Windows Server Containers в среде физических серверов:
так и Hyper-V Containers на базе виртуальных машин (подробнее об этом - тут):
В прошлом превью поддерживалась только технология Windows Server Containers, теперь же Microsoft сделала публичной технологию Hyper-V Containers. Она позволяет развертывать виртуальные сервисы в контейнерах в средах с повышенной изоляцией на базе виртуальных машин на платформе Hyper-V. Аналогичный подход компания VMware предлагает и в своей платформе vSphere с технологией vSphere Integrated Containers.
Ниже можно посмотреть живую демонстрацию технологии Hyper-V Containers от легендарного Марка Руссиновича:
Документация о контейнерах на платформе Windows Server доступна вот тут.
2. Улучшения Nano Server.
Напомним, что об этом решении мы также писали вот тут. Nano Server как раз подходит как среда исполнения для контейнеров Docker (но не только). По сравнению с прошлым превью Windows Server в данной версии Nano Server появились следующие улучшения:
Поддержка роли DNS server
Поддержка роли IIS
Поддержка технологии MPIO
Средства Virtual Machine Manager (VMM)
Поддержка интерфейса мониторинга SCOM
Работа с режимом PowerShell DSC (Desire State Configuration) для развертывания и настройки новых систем
Поддержка технологии DCB (Data Center Bridging)
Улучшенный установщик Windows Server Installer
Инструментарий WMI для механизма Windows Update
Поддержка пакетов AppX
3. Поддержка вложенной виртуализации Hyper-V.
Об этом мы весьма подробно писали вот тут. Ранее эти средства были доступны в сборках Windows 10, теперь же возможность была добавлена и в Windows Server.
4. Поддержка Direct Device Assignment (проброс устройств на шине PCIe).
Теперь в Windows Server появился полноценный прямой проброс PCI-устройств в виртуальные машины. Если ранее поддерживалась только технология SR-IOV для сетевых адаптеров, то теперь Direct Device Assignment можно применять для любых устройств на шине PCI Express, например, для устройств хранения на базе Flash-накопителей (см. раскрытое устройство Dell):
Это позволит превратить вашу виртуальную машину в сервер хранения как Virtual Storage Appliance (например, для тех же виртуальных машин) с прямым доступом к хранилищу.
5. Улучшения технологии Storage Spaces Direct (S2D).
Теперь в рамках данной технологии появилась поддержка виртуальных дисков Multi-Resilient Virtual Disks, которые представляют собой так называемый "3D-RAID", то есть каждый виртуальный диск содержит в себе зеркальные копии данных других дисков, кодированные по алгоритму с контролем четности (это позволяет создавать избыточность любой глубины на уровне виртуальных дисков):
Все данные записываются в Mirror tier (это часть виртуального диска с наибольше производительностью underlying storage), а в Parity tier уходят избыточные данные для коррекции ошибок в случае сбоев. Операционная система ReFS всегда записывает данные сначала в mirror tier, а если требуется апдейт parity tier, то он идет следом. Таким образом достигается полная надежность рабочего процесса изменения данных:
Нечто подобное (на простейшем уровне) используется в решении VMware Virtual SAN (а в следующей версии будет еще круче). Более подробнее о технологии S2D можно почитать вот тут.
6. Прочие улучшения.
Среди прочего, появилась поддержка технологии Virtual Machine Multi-Queue для виртуальных машин, позволяющей максимально эффективно использовать сети 10G+. Также были расширены возможности технологии Just Enough Administration (JEA), предоставляющей только самые необходимые инструменты для таких серверных ролей, как, например, контроллер домена, которые требуют максимального уменьшения поверхности возможной атаки.
Также интересно, что теперь в разделе документации по платформе Hyper-V в Windows 10 была добавлена возможность самому внести вклад в разделы о продуктах и технологиях (нужно нажать "Contribute to this topic"):
Скачать Windows Sever 2016 Technical Preview 4 можно по этой ссылке. Подробно обо всех нововведениях обновленного превью можно прочитать вот здесь.
Как-то раз мы писали про баг в VMware vSphere 5.5 (и более ранних версиях), заключавшийся в том, что при увеличении виртуальных дисков машин с включенной технологией Changed Block Tracking (CBT) их резервные копии оказывались невалидными и не подлежащими восстановлению. Эта ошибка была через некоторое время пофикшена.
Суть критического бага в том, что операции ввода-вывода, сделанные во время консолидации снапшота ВМ в процессе снятия резервной копии, могут быть потеряны. Для первого бэкапа в этом нет ничего страшного, а вот вызываемая во второй раз функция QueryDiskChangedAreas технологии CBT не учитывает потерянные операции ввода-вывода, а соответственно при восстановлении из резервной копии такой бэкап будет неконсистентным. То есть баг намного более серьезный, чем был в версии vSphere 5.5 (там надо были задеты только ВМ, диски которых увеличивали, а тут любая ВМ подвержена багу).
На данный момент решения этой проблемы нет, надо ждать исправления ошибки. Пока VMware предлагает на выбор 3 варианта:
Сделать даунгрейд хостов ESXi на версию 5.5, а версию virtual hardware 11 понизить на 10.
Делать полные бэкапы виртуальных машин (full backups) вместо инкрементальных.
Выключать виртуальные машины во время инкрементального бэкапа, чтобы у них не было никаких IO, которые могут потеряться.
Как вы понимаете, ни один из этих вариантов неприемлем в условиях нормальной работы производственной среды. Мы оповестим вас об исправлении ошибки, ну а пока поздравляем службу контроля качества компании VMware с очередной лажей!
P.S. Пока делайте полные бэкапы критичных систем. И следите за новостями от Veeam.
Сегодняшняя статья расскажет вам ещё об одной функции моего PowerShell-модуля для управления виртуальной инфраструктурой VMware - Vi-Module. Первая статья этой серии с описанием самого модуля находится здесь. Функция Convert-VmdkThin2EZThick. Как вы уже поняли из её названия, функция конвертирует все «тонкие» (Thin Provision) виртуальные диски виртуальной машины в диски типа Thick Provision Eager Zeroed.
Многие из вас знают, что в VMware vSphere есть такой режим работы виртуальных дисков, как Raw Device Mapping (RDM), который позволяет напрямую использовать блочное устройство хранения без создания на нем файловой системы VMFS. Тома RDM бывают pRDM (physical) и vRDM (virtual), то есть могут работать в режиме физической и виртуальной совместимости. При работе томов в режиме виртуальной совместимости они очень похожи на VMFS-тома (и используются очень редко), а вот режим физической совместимости имеет некоторые преимущества перед VMFS и довольно часто используется в крупных предприятиях.
Итак, для чего может быть полезен pRDM:
Администратору требуется использовать специальное ПО от производителя массива, которое работает с LUN напрямую. Например, для создания снапшотов тома, реплики базы данных или ПО, работающее с технологией VSS на уровне тома.
Старые данные приложений, которые еще не удалось перенести в виртуальные диски VMDK.
Виртуальная машина нуждается в прямом выполнении команд к тому RDM (например, управляющие SCSI-команды, которые блокируются слоем SCSI в VMkernel).
Перейдем к рассмотрению схемы решения VMware Site Recovery Manager (SRM):
Как вы знаете, продукт VMware SRM может использовать репликацию уровня массива (синхронную) или технологию vSphere Replication (асинхронную). Как мы писали вот тут, если вы используете репликацию уровня массива, то поддерживаются тома pRDM и vRDM, а вот если vSphere Replication, то репликация физических RDM будет невозможна.
Далее мы будем говорить о репликации уровня дискового массива томов pRDM, как о самом часто встречающемся случае.
Если говорить об уровне Storage Replication Adapter (SRA), который предоставляется производителем массива и которым оперирует SRM, то SRA вообще ничего не знает о томах VMFS, то есть о том, какого типа LUN реплицируется, и что на нем находится.
Он оперирует понятием только серийного номера тома, в чем можно убедиться, заглянув в XML-лог SRA:
Тут видно, что после серийного номера есть еще и имя тома - в нашем случае SRMRDM0 и SRMVMFS, а в остальном устройства обрабатываются одинаково.
SRM обрабатывает RDM-диски похожим на VMFS образом. Однако RDM-том не видится в качестве защищаемых хранилищ в консоли SRM, поэтому чтобы добавить такой диск, нужно добавить виртуальную машину, к которой он присоединен, в Protection Group (PG).
Допустим, мы добавили такую машину в PG, а в консоли SRM получили вот такое сообщение:
Device not found: Hard disk 3
Это значит одно из двух:
Не настроена репликация RDM-тома на резервную площадку.
Репликация тома настроена, но SRM еще не обнаружил его.
В первом случае вам нужно заняться настройкой репликации на уровне дискового массива и SRA. А во втором случае нужно пойти в настройки SRA->Manage->Array Pairs и нажать там кнопку "Обновить":
Этот том после этого должен появиться в списке реплицируемых устройств:
Далее в настройках защиты ВМ в Protection Group можно увидеть, что данный том видится и защищен:
Добавление RDM-диска к уже защищенной SRM виртуальной машине
Если вы просто подцепите диск такой ВМ, то увидите вот такую ошибку:
There are configuration issues with associated VMs
Потому, что даже если вы настроили репликацию RDM-диска на уровне дискового массива и SRA (как это описано выше), он автоматически не подцепится в настройки - нужно запустить редактирование Protection Group заново, и там уже будет будет виден RDM-том в разделе Datastore groups (если репликация корректно настроена):
Помните также, что SRM автоматически запускает обнаружение новых устройств каждые 24 часа по умолчанию.
Гостевая статья нашего спонсора - компании ИТ-ГРАД, предоставляющей услуги виртуальных машин VMware в аренду. В этой статье речь пойдет о плюсах интеграции среды виртуализации VMware и систем хранения NetApp. В частности, продолжим разбираться с VAAI и посмотрим, как использование такой связки может помочь в проектах по разработке ПО.
На блоге vSphere появилась отличная статья о сервисах семейства vCenter Server Watchdog, которые обеспечивают мониторинг состояния различных компонентов vCenter, а также их восстановление в случае сбоев. Более подробно о них также можно прочитать в VMware vCenter Server 6.0 Availability Guide.
Итак, сервисы Watchdog бывают двух типов:
PID Watchdog - мониторит процессы, запущенные на vCenter Server.
API Watchdog - использует vSphere API для мониторинга функциональности vCenter Server.
Сервисы Watchdog пытаются рестартовать службы vCenter в случае их сбоя, а если это не помогает, то механизм VMware перезагружает виртуальную машину с сервером vCenter на другом хосте ESXi.
PID Watchdog
Эти службы инициализируются во время инициализации самого vCenter. Они мониторят только службы, которые активно работают, и если вы вручную остановили службу vCenter, поднимать он ее не будет. Службы PID Watchdog, контролируют только лишь наличие запущенных процессов, но не гарантируют, что они будут обслуживать запросы (например, vSphere Web Client будет обрабатывать подключения) - этим занимается API Watchdog.
Вот какие сервисы PID Watchdog бывают:
vmware-watchdog - этот watchdog обнаруживает сбои и перезапускает все не-Java службы на сервере vCenter Server Appliance (VCSA).
Java Service Wrapper - этот watchdog обрабатывает сбои всех Java-служб на VCSA и в ОС Windows.
Likewise Service Manager - данный watchdog отвечает за обработку отказов всех не-Java служб сервисов platform services.
Windows Service Control Manager - отвечает за обработку отказов всех не-Java служб на Windows.
vmware-watchdog
Это шелл-скрипт (/usr/bin/watchdog), который располагается на виртуальном модуле VCSA. Давайте посмотрим на его запущенные процессы:
Давайте разберем эти параметры на примере наиболее важной службы VPXD:
-a
-s vpxd
-u 3600
-q 2
Это означает, что:
vpxd (-s vpxd) запущен (started), для него работает мониторинг, и он будет перезапущен максимум дважды в случае сбоя (-q 2). Если это не удастся в третий раз при минимальном аптайме 1 час (-u 3600 - число секунд), виртуальная машина будет перезагружена (-a).
Он основан на Tanuki Java Service Wrapper и нужен, чтобы обнаруживать сбои в Java-службах vCenter (как обычного, так и виртуального модуля vCSA). Вот какие службы мониторятся:
Если Java-приложение или JVM (Java Virtual Machine) падает, то перезапускается JVM и приложение.
Likewise Service Manager
Это сторонние средства Likewise Open stack от компании BeyondTrust, которые мониторят доступность следующих служб, относящихся к Platform Services среды vCenter:
VMware Directory Service (vmdir)
VMware Authentication Framework (vmafd, который содержит хранилище сертификатов VMware Endpoint Certificate Store, VECS)
VMware Certificate Authority (vmca)
Likewise Service Manager следит за этими сервисами и перезапускает их в случае сбоя или если они вываливаются.
mgmt01vc01.sddc.local:~ # /opt/likewise/bin/lwsm list | grep vm vmafd running (standalone: 5505) vmca running (standalone: 5560) vmdir running (standalone: 5600)
Вместо параметра list можно также использовать start и stop, которые помогут в случае, если одна из этих служб начнет подглючивать. Вот полный список параметров Likewise Service Manager:
list List all known services and their status autostart Start all services configured for autostart start-only <service> Start a service start <service> Start a service and all dependencies stop-only <service> Stop a service stop <service> Stop a service and all running dependents restart <service> Restart a service and all running dependents refresh <service> Refresh service's configuration proxy <service> Act as a proxy process for a service info <service> Get information about a service status <service> Get the status of a service gdb <service> Attach gdb to the specified running service
А вот таким образом можно узнать детальную информацию об одном из сервисов:
Помните также, что Likewise Service Manager отслеживает связи служб и гасит/поднимает связанные службы в случае необходимости.
API Watchdog
Этот сервис следит через vSphere API за доступностью самого важного сервиса vCenter - VPXD. В случае сбоя, этот сервис постарается 2 раза перезапустить VPXD, и если это не получится - он вызовет процедуру перезапуска виртуальной машины механизмом VMware HA.
Эти службы инициализируются только после первой загрузки после развертывания или обновления сервисов vCenter. Затем каждые 5 минут через vSphere API происходит аутентификация и опрос свойства rootFolder для корневой папки в окружении vCenter.
Далее работает следующий алгоритм обработки отказов:
Первый отказ = Restart Service
Второй отказ = Restart Service
Третий отказ = Reboot Virtual Machine
Сброс счетчика отказов происходит через 1 час (3600 секунд)
Перед рестартом сервиса VPXD, а также перед перезагрузкой виртуальной машины, служба API Watchdog генерирует лог, который можно исследовать для решения проблем:
storage/core/*.tgz - на виртуальном модуле VCSA
C:\ProgramData\VMware\vCenterServer\data\core\*.tgz - не сервере vCenter
Конфигурация сервиса API Watchdog (который также называется IIAD - Interservice Interrogation and Activation Daemon) хранится в JSON-формате в файле "iiad.json", который можно найти по адресу /etc/vmware/ на VCSA или C:\ProgramData\VMware\vCenterServer\cfg\iiad.json на Windows-сервер vCenter:
requestTimeout – дефолтный таймаут для запросов по умолчанию.
hysteresisCount – позволяет отказам постепенно "устаревать" - каждое такое значение счетчика при отказе, число отсчитываемых отказов будет уменьшено на один.
rebootShellCmd – указанная пользователем команда, которая будет исполнена перед перезапуском ВМ.
restartShellCmd – указанная пользователем команда, которая будет исполнена перед перезапуском сервиса.
maxTotalFailures – необходимое число отказов по всем службам, которое должно случиться, чтобы произошел перезапуск виртуальной машины.
needShellOnWin – определяет, нужно ли запускать сервис с параметром shell=True на Windows.
watchdogDisabled – позволяет отключить API Watchdog.
vpxd.watchdogDisabled – позволяет отключить API Watchdog для VPXD.
createSupportBundle – нужно ли создавать support-бандл перед перезапуском сервиса или рестартом ВМ.
automaticServiceRestart – нужно ли перезапускать сервис при обнаружении сбоя или просто записать это в лог.
automaticSystemReboot – нужно ли перезапускать ВМ при обнаружении сбоя или просто записать в лог эту рекомендацию.
Мы уже не раз писали про VMware ESXi Embedded Host Client, который возвращает полноценный веб-клиент для сервера VMware ESXi с возможностями управления хостом и виртуальными машинами, а также средствами мониторинга производительности.
Теперь для этого продукте есть offline bundle, который можно накатывать с помощью VMware Update Manager, как на VMware vSphere 5.x, так и на VMware vSphere 6.x.
Одна из долгожданных фичей этого релиза - возможность просматривать и редактировать разделы дисков ESXi:
Если у вас есть это средство второй версии, то обновиться на третью можно с помощью следующей команды:
За прошедшие недели мы достаточно многописали о новостях с VMware VMworld 2015 (как в Америке, так и в Европе). Не так давно компания ИТ-ГРАД, ведущий хостинг-провайдер VMware IaaS в России, опубликовала свою версию основных новостей с VMworld.
Давайте посмотрим, какие анонсы показались коллегам наиболее важными:
15 самых горячих технологических новинок с VMworld 2015
Многие годы VMware формирует будущее корпоративных ИТ-технологий, продвигая идею программно-определяемого ЦОД. Несмотря на растущую конкуренцию, компания до сих пор занимает лидирующие позиции на рынке виртуализации. Столь продвинутую и технически совершенную виртуальную инфраструктуру помогают формировать и многочисленные стратегические партнеры VMware, представившие свои новинки на недавно отгремевшей конференции VMworld 2015. Мы не могли пройти мимо любопытного списка технических новшеств конференции, который опубликовали коллеги из cio.com, и отобрали 15 самых интересных новинок. Спешим поделиться.
1. Unity EdgeConnect
Если попытаться одной фразой объяснить, что делает это устройство, то получится как-то так: Unity EdgeConnect позволяет компаниям упростить и удешевить построение WAN с помощью использования технологий SD-WAN для существующего широкополосного подключения. Фактически требуется подключить такие устройства с обеих сторон (в головном офисе и филиале) и через Unity Orchestrator выполнить связь устройств буквально в пару кликов. Впрочем, лучше посмотреть своими глазами — вот коротенькое видео.
Unity EdgeConnect уже доступен для заказа и обойдется примерно в $199/мес. для каждого сайта.
2. Soha Cloud
Облако Soha Cloud позволяет добавить безопасности вашим облачным приложениям. Продукт выступает в качестве «прослойки» (AirGAP) между облачными приложениями и сетью Интернет, что уменьшает поверхность потенциальной атаки до нуля и прячет приложения от публики. Подробности о технологии можно почерпнуть на сайте SOHA.
Стоимость сервиса стартует с отметки $5/мес. на пользователя, а опробовать его можно уже сейчас.
3. PRTG Network Monitor
PRTG Network Monitor — это система мониторинга для стартапов и небольших компаний. Продукт позволяет выполнять мониторинг состояния и производительности всей инфраструктуры, включая облако и виртуальную среду (например, есть «сенсоры» для серверов VMware и виртуальных машин). Стоимость лицензии зависит от приобретаемого числа сенсоров, причем до 100 штук можно мониторить совершенно бесплатно.
Больше 5 лет назад мы писали о технологии VMware Storage I/O Control (SIOC), которая позволяет приоритизировать ввод-вывод для виртуальных машин в рамках хоста, а также обмен данными хостов ESXi с хранилищами, к которым они подключены. С тех пор многие администраторы применяют SIOC в производственной среде, но не все из них понимают, как именно это работает.
На эту тему компания VMware написала два интересных поста (1 и 2), которые на практических примерах объясняют, как работает SIOC. Итак, например, у нас есть вот такая картинка:
В данном случае мы имеем хранилище, отдающее 8000 операций ввода-вывода в секунду (IOPS), к которому подключены 2 сервера ESXi, на каждом из которых размещено 2 виртуальных машины. Для каждой машины заданы параметры L,S и R, обозначающие Limit, Share и Reservation, соответственно.
Напомним, что:
Reservation - это минимально гарантированная производительность канала в операциях ввода-вывода (IOPS). Она выделяется машине безусловно (резервируется для данной машины).
Shares - доля машины в общей полосе всех хостов ESXi.
Limit - верхний предел в IOPS, которые машина может потреблять.
А теперь давайте посмотрим, как будет распределяться пропускная способность канала к хранилищу. Во-первых, посчитаем, как распределены Shares между машинами:
Общий пул Shares = 1000+2500+500+1000 = 5000
Значит каждая машина может рассчитывать на такой процент канала:
Если смотреть с точки зрения хостов, то между ними канал будет поделен следующим образом:
ESX1 = 3500/5000 = 70%
ESX2 = 1500/5000 = 30%
А теперь обратимся к картинке. Допустим у нас машина VM1 простаивает и потребляет только 10 IOPS. В отличие от планировщика, который управляет памятью и ее Shares, планировщик хранилищ (он называется mClock) работает по другому - неиспользуемые иопсы он пускает в дело, несмотря на Reservation у это виртуальной машины. Ведь он в любой момент может выправить ситуацию.
Поэтому у первой машины остаются 1590 IOPS, которые можно отдать другим машинам. В первую очередь, конечно же, они будут распределены на этом хосте ESXi. Смотрим на машину VM2, но у нее есть LIMIT в 5000 IOPS, а она уже получает 4000 IOPS, поэтому ей можно отдать только 1000 IOPS из 1590.
Следовательно, 590 IOPS уйдет на другой хост ESXi, которые там будут поделены в соответствии с Shares виртуальных машин на нем. Таким образом, распределение IOPS по машинам будет таким:
Все просто и прозрачно. Если машина VM1 начнет запрашивать больше канала, планировщик mClock начнет изменять ситуацию и приведет ее к значениям, описанным выше.
В этой заметке мы расскажем еще об одной важной новой функции пакета продуктов - Scale-out Backup Repository. Ранее пользователи Veeam Backup and Replication использовали различные устройства для бэкап-репозиториев, чтобы хранить резервные копии виртуальных машин. Это могли быть локальные диски серверов, файловые хранилища, разделы на СХД и многое другое. Так как инфраструктура растет постепенно и, зачастую, неоднородно, в итоге у администраторов оказывался примерно вот такой наборчик бэкап-репозиториев:
Эта картина плоха со всех сторон. Во-первых, таким большим числом репозиториев трудно управлять - надо следить за их доступностью, поддерживать схемы именования, смотреть за свободным пространством и т.п. Все это создает серьезные административные проблемы в большой инфраструктуре.
Во-вторых, число бэкап-задач, которые создает администратор - как минимум равно числу бэкап-репозиториев, так как одна задача не может охватывать 2 репозитория.
Ну и, в третьих, посмотрите на свободное место на каждом репозитории - его весьма много (если брать среднее, то 30%). То есть, мы используем вполовину больше того, что нам требуется.
Эта ситуация давно волновала администраторов, и в новой версии Veeam Availability Suite v9 представлена функция Scale-out Backup Repository, которая позволяет объединить все репозитории в один мета-объект (global pool), который можно задавать в качестве целевого хранилища бэкапов. Для расширения такого пула потребуется лишь добавить экстент (extent), который повысит совокупную емкость глобального репозитория. Удобно и не надо перераспределять целевые хранилища, чтобы найти свободное место под новые бэкапы.
Таким образом, можно использовать единственную задачу резервного копирования всех нужных вам машин, указав в качестве целевого этот глобальный репозиторий. При этом глобальный репозиторий можно наращивать хранилищами любого типа - локальные диски серверов, сетевые хранилища и даже, например, дедуплицирующие физические или виртуальные модули (dedup appliances) - все это для Veeam Backup and Replication будет поддерживаться и работать.
При добавлении экстента можно указать, принимает ли он полные бэкапы (full backups), инкрементальные бэкапы (incremental backups) или оба типа. Например, для инкрементальных бэкапов можно использовать быстрые all-flash хранилища, а для полных бэкапов можно применять dedup appliance в качестве целевого хранилища резервных копий, где они будут лежать в дедуплицированном виде. Возможности для фантазии тут безграничны.
Также происходит, по-сути, появление бэкап-облака, нового уровня абстракции, которое представляется пользователям как единое пространство хранения резервных копий, а его обслуживанием занимается бэкап-администратор. Теперь владельцы систем могут сами настраивать бэкап своих виртуальных машин в единое облако, не думая, какой репозиторий выбрать, а бэкап-администратор уже займется оптимизацией своего облака.
Более подробно об этом всем написано в блоге Veeam.
Бывает так, что на виртуальной или физической машине заканчивается свободное место на диске, где расположена база данных для VMware vCenter. Чаще всего причина проста - когда-то давно кто-то не рассчитал размер выделенного дискового пространства для сервера, где установлен vCenter и SQL Server Express.
В этом случае в логах (в SQL Event Log Viewer и SQL Log) будут такие ошибки:
Could not allocate space for object ‘dbo.VPX_EVENT_ARG’.’PK_VPX_EVENT_ARG’ in database ‘VIM_VCDB’ because the ‘PRIMARY’ filegroup is full. Create disk space by deleting unneeded files, dropping objects in the filegroup, adding additional files to the filegroup, or setting autogrowth on for existing files in the filegroup.
CREATE DATABASE or ALTER DATABASE failed because the resulting cumulative database size would exceed your licensed limit of 4096 MB per database.
Could not allocate space for object 'dbo.VE_event_historical'.'PK__VE_event_histori__00551192' in database 'ViewEvent' because the 'PRIMARY' filegroup is full. Create disk space by deleting unneeded files, dropping objects in the filegroup, adding additional files tothe filegroup, or setting autogrowth on for existing files in the filegroup.
Решение в данном случае простое - нужно выполнить операцию по очистке старых данных из БД SQL Server (Shrink Database). Делается это в SQL Management Studio - нужно выбрать базу данных и выполнить Tasks -> Shrink -> Database:
Смотрим, что получится и нажимаем Ok:
Также в KB 1025914 вы найдете более детальную информацию о том, как почистить базы данных Microsoft SQL Server и Oracle. Там же есть и скрипты очистки БД:
Мероприятие пройдет 20 октября в 22-00 по московскому времени.
На вебинаре будет рассказано, почему в гиперконвергентной инфраструктуре лучше иметь 3 узла для организации отказоустойчивых хранилищ. Напомним, что мы уже писали об этой архитектуре вот тут.
После выхода новой версии платформы VMware vSphere 6 перед многими администраторами встал вопрос об обновлении различных компонентов виртуальной инфраструктуры. На крупных предприятиях, как правило, используется не только платформа VMware ESXi и сервисы управления vCenter, но и различные корпоративные продукты, такие как VMware Horizon View для инфраструктуры виртуальных ПК или VMware vRealize Operations (vROPs) для мониторинга и решения проблем.
Вот в какой правильной последовательности нужно обновлять решения VMware (если у нескольких продуктов очередь одна - их можно обновлять в любой последовательности):
Продукт
VMware
Последовательность обновления (очередность)
vCenter
Single Sign-On (SSO)
1
vRealize Automation (vRA), бывший vCloud Automation Center
2
vRealize Configuration Manager (VCM), бывший vCenter Configuration Manager
2
vRealize Business (он же ITBM - VMware IT Business Management)
2
vRealize Automation Application Services (vRAS), бывший vSphere AppDirector
3
vCloud Director (vCD)
3
vCloud Networking and Security (vCNS)
4
NSX Manager
4
NSX Controllers
5
View Composer
5
View Connection Server
6
vCenter Server
7
vRealize Orchestrator (vRO), он же vCenter Orchestrator
8
vSphere Replication (VR)
8
vCenter Update Manager (VUM)
8
vRealize Operations Manager (vROPs) / он же vCenter Operations Manager (vCOPs)
8
vSphere Data Protection (VDP)
8
vCenter Hyperic
8
vCenter Infrastructure Navigator (VIN)
8
vCloud Connector (vCC)
9
vRealize Log Insight (vRLI)
9
vSphere Big Data Extension (BDE)
9
vCenter Site Recovery Manager (SRM)
9
ESXi
10
VMware Tools
11
vShield / NSX / Edge
11
vShield App/ NSX LFw
12
vShield Endpoint / NSX Guest IDS
12
View Agent / Client
12
О проведении операций по обновлению компонентов решений VMware более подробно рассказано в статье KB 2109760. Там же приведены примеры сценариев обновления, если у вас есть определенный набор продуктов.
Кстати, помните, что после обновления на VMware vSphere 6.0 вы не сможете использовать продукт VMware Storage Appliance, который больше не поддерживается.
Этой статьёй я хочу открыть серию статей, целью каждой из которых будет описание одной из написанных мной функций PowerCLI или так называемых командлетов (cmdlets), предназначенных для решения задач в виртуальных инфраструктурах, которые невозможно полноценно осуществить с помощью только лишь встроенных функций PowerCLI. Все эти функции будут объединены в один модуль - Vi-Module. Как им пользоваться, можете почитать здесь.
15 октября в 15:00 ИТ-ГРАД проводит презентацию новых высокопроизводительных флеш-массивов AFF от NetApp. На мероприятии вы узнаете о новой расширенной линейке флеш-массивов СХД, разработанной для корпоративных клиентов. Спикерами мероприятия выступят инженеры NetApp и ИТ-ГРАД. Таги:
Иногда администраторам хранилищ в VMware vSphere требуется передать логический том LUN или локальный диск сервера под другие цели (например, отдать не под виртуальные системы или передать в другой сегмент виртуальной инфраструктуры). В этом случае необходимо убедиться, что все данные на этом LUN удалены и не могут быть использованы во вред компании.
Раньше это приходилось выполнять путем загрузки из какого-нибудь Linux LiveCD, которому презентован данный том, и там удалять его данные и разделы. А в VMware vSphere 6 Update 1 появился более простой способ - теперь эта процедура доступна из графического интерфейса vSphere Web Client в разделе Manage->Storage Adapters:
Теперь просто выбираем нужный адаптер подсистемы хранения и нажимаем Erase для удаления логических томов устройства (будут удалены все логические тома данного устройства):
Теперь можно использовать этот локальный диск по другому назначению, например, отдать кластеру VSAN.
Ну и также отметим, что в следующей версии утилиты ESXi Embedded Host Client компания VMware сделает возможность не только удаления таблицы разделов, но и добавит средства их редактирования:
Компания StarWind Software, известная своим лучшим продуктом для созданиях отказоустойчивых хранилищ для VMware vSphere и Microsoft Hyper-V, на отдельном подсайте сделала доступной базу знаний StarWind Knowledge Base.
Статьи KB разбиты по категориям, по всей базе доступен поиск, к каждой статье есть тэги. На данный момент в базе 41 статья, среди которых есть несколько полезных в плане обучения, например, Logical block size или StarWind LSFS FAQ.
Скачать пробную версию продукта StarWind Virtual SAN можно по этой ссылке.
Мы уже писали о новой версии решения VMware Virtual SAN 6.1, предназначенной для создания отказоустойчивых хранилищ на платформе VMware vSphere. После того, как издания "hybrid" и "all-flash" были переименованы в "standard" и "advanced" соответственно, у пользователей появилось несколько вопросов о функциональности этих изданий.
Начнем с того, что в целом все осталось как было:
VSAN
STANDARD
VSAN
ADVANCED
VSAN FOR ROBO
(25 VM PACK)
Политики хранилищ Storage Policy Based Management (SPBM)
Итак, мы видим, что отличий у изданий Standard и Advanced теперь два:
Для конфигураций только из SSD-дисков серверов можно использовать только издание Advanced.
Для "растянутых" кластеров также можно использовать только издание Advanced. Но тут есть нюанс - растянутым кластером можно считать географически разнесенные площадки (на уровне двух разных зданий). Если у вас кластер на уровне стоек в двух серверных или на разных этажах - растянутым он не считается.
Также появилось издание VSAN for ROBO (remote or branch offices). Это издание позволяет использовать решение VSAN компаниям имеющую сеть небольших филиалов, где нет большого числа хостов ESXi. Для такой лицензии можно запустить не более 25 виртуальных машин в рамках филиала и одной ROBO-лицензии.
Здесь кластеры строятся на уровне каждого из филиалов, а witness-компонент (виртуальный модуль, следящий за состоянием кластера) располагается в инфраструктуре центрального офиса. Причем на каждый кластер VSAN нужно по отдельному witness'у. Этот самый witness позволяет построить кластер на базе всего двух узлов, а не трех, так как он следит за ситуацией split brain в кластере. Это позволяет удешевить решение для филиала, использовав для инфраструктуры из 25 машин всего 2 сервера. Более подробно о ROBO-сценарии написано вот тут.
А вот как выглядит настройка ROBO-издания Virtual SAN:
Ну и, само собой, ROBO-сценарии можно реализовывать по своему усмотрению на лицензиях Standard или Advanced.

 RSS
RSS







































































{kind=link}

